
 چیست؟")


















خرید LTO-9 TECHNOLOGY
و داده های کاربران
قابلیت اطمینان LTO-9
تحلیل و بررسی LTO-9
در این مقاله، ما قابلیت اطمینان کدهای تصحیح خطای LTO-9 را برای پشتیبانی از قابلیت اطمینان داده های کاربر LTO-9 تحلیل می کنیم که بهتر از 1 رخداد خطای غیرقابل اصلاح در 10-20 بیت کاربر منتقل شده است که معمولاً به عنوان نرخ خطای بیت غیرقابل اصلاح (UBER) شناخته می شود. به حداقل 12 NINES دوام ترجمه می شود. چندین فناوری وجود دارد که LTO-9 را قادر می سازد تا 10 برابر پیشرفت های UBER را نسبت به LTO-8 انجام دهد. ما نشان خواهیم داد که در صورت تخریب هر یک از 32 کانال نیز این مورد قابل اجرا است.
بخش 1 – فناوری LTO-9
در طول 2 دهه گذشته از زمان معرفی LTO در سال 2000 با ظرفیت 100 گیگابایت، ظرفیت ذخیره سازی کارتریج های LTO 180 برابر و نرخ داده ها 20 برابر افزایش یافته است. همچنین در طول این مدت، نرخ خطای بیت غیرقابل تصحیح پایان عمر (EOL) (UBER) کارتریج های LTO نیز با ضریب 1000، 3 مرتبه، بهبود یافته است. فرمت Linear Tape Open 9 (LTO-9) که به تازگی منتشر شده است، ظرفیت کارتریج اصلی 18 ترابایت و نرخ خطای بیت غیرقابل اصلاح (UBER) 10-20 را ارائه می دهد. نسبت به قالب نسل قبلی LTO-8، این مربوط به افزایش 50 درصدی ظرفیت و بهبود 10 برابری در UBER است. یک UBER 10-20 به ازای هر 12.5 اگزابایت داده خوانده شده، یک رخداد خطای خواندن غیرقابل بازیابی را نشان می دهد. افزایش همزمان ظرفیت و بهبود قابلیت اطمینان با ترکیبی از فناوری های جدید پیاده سازی شده در LTO-9 امکان پذیر شد. با استفاده از ارقام تقریبی، افزایش ظرفیت 50 درصدی با افزایش چگالی سطحی (AD) به میزان 41 درصد از طریق ترکیب 35 درصد تراکم مسیر (TD) بیشتر و 4 درصد چگالی خطی بیشتر (LD) بهعلاوه، Tape طولانیتر به دست آمد. طول آن بیش از 1 کیلومتر (1035 متر) است.
افزایش چگالی سطحی در ضبط مغناطیسی منجر به از دست دادن SNR می شود که با معادله معروف زیر توضیح داده می شود:
که در آن، D = قطر دانه، B طول بیت (چگالی خطی Linear Density) و W عرض بیت/خواننده (Track Density) است.  ثابت میکرو مغناطیسی است.
ثابت میکرو مغناطیسی است.
متغیر γ نسبت چگالی نرمال شده برای یک چگالی خطی معین و شکل پالس است که با طراحی TMR head نیز تعیین می شود.
متغیر α پارامتر انتقال است که تابعی از ویژگی های مغناطیسی لایه ضبط و فاصله head تا Tape است. ویژگیهای ذرات مغناطیسی، فاصلهبندی tape-head و طراحی TMR head همگی نقشهای کلیدی برای SNR دارند. مقیاسبندی چهارگانه SNR با B و مقیاسگذاری خطی با W باعث میشود که از نظر SNR برای مقیاس TD در مقایسه با LD هزینه کمتری داشته باشد و انگیزهای برای مقیاسبندی 35 درصد TD در مقایسه با مقیاسبندی LD 4 درصد اجرا شده در LTO-9 است. به طور کلی، کاهش SNR منجر به افزایش نرخ خطا و در نتیجه کاهش قابلیت اطمینان خواهد شد. برای جلوگیری از چنین کاهشی در قابلیت اطمینان، از دست دادن SNR ناشی از مقیاسبندی AD باید با پیشرفتهایی در فناوری ضبط جبران شود. در LTO-9 این کار با استفاده از فناوریهای درایو جدید انجام شد که شامل یک رابط head به Tape (head-to-tape) بهینهشده جدید، خوانندههای TMR (مقاومت مغناطیسی تونل) با حساسیت بالاتر و یک نویسنده بهینهسازی شده است.
علاوه بر این، LTO-9 از یک رسانه جدید با ذرات BaFe بهبود یافته استفاده می کند که بر اساس یک بستر نازک تر با پایداری بهینه است. مقیاس بندی تراکم مسیر 35% که در LTO-9 اجرا شده است با کاهش عرض هد خواندن در ترکیب با بهبود عملکرد ردیابی به دست آمد. در LTO-9 Tape Dimensional Variations (TDV) زیرلایه جدید که به دلیل تغییرات در شرایط محیطی ایجاد می شود، از طریق یک الگوریتم کالیبراسیون یک بار در Tape منحصر به فرد مدیریت می شود که به سیستم عامل پیچیده درایو برای کنترل ضبط مغناطیسی 32 کانال با استفاده از بسته کمک می کند. الگوریتم های سروو حلقه قابلیت اطمینان LTO-9 با استفاده از کد تصحیح خطای C2 بسیار کارآمد بر اساس کد تصحیح خطای Reed-Solomon با طول بلوک بیشتر بهبود یافت. این فناوریها با هم باعث افزایش 50 درصدی ظرفیت و بهبود 10 برابری نرخ خطای بیت غیرقابل اصلاح (UBER) LTO-9 به 10-20 شدند.
بخش 2 – LTO-8/9 Format Background
برای درک بهتر چگونگی دستیابی به این بهبود قابلیت اطمینان، ابتدا مروری بر نحوه چیدمان و محافظت داده ها توسط کدهای تصحیح خطا در قالب های LTO-8 و LTO-9 مفید است. در تمام نسلهای LTO تا به امروز، دادههای کاربر به مجموعه دادهها و هر مجموعه داده به چندین مجموعه داده فرعی تقسیم میشود. هر مجموعه داده فرعی شامل چندین بلوک داده مستطیلی به هم پیوسته است و توسط یک کد محصول که شامل دو کد جزء Reed-Solomon به نامهای C1 و C2 است محافظت میشود. هر بلوک داده مستطیلی را می توان به عنوان یک ماتریس مشاهده کرد و قبل از اینکه روی Tape نوشته شود، یک مرحله رمزگذاری کد محصول C1-C2 را طی می کند. برای تجسم این فرآیند رمزگذاری، مستطیلی از بایت های داده کاربر به اندازه k2 × k1 را در نظر بگیرید. ابتدا ردیفهای ماتریس با استفاده از کد Reed-Solomon (n1, k1) کدC1) ) کدگذاری میشوند. سپس ستونهای ماتریس کدگذاری شده با ردیف جدید اکنون به اندازه k2 × n1) با (n2, k2) کد RS کد =( C2) کدگذاری میشوند تا بلوک دادههای کدگذاری شده نهایی (n2 × n1) همانطور که در شکل 1 در زیر نشان داده شده است ایجاد شود.
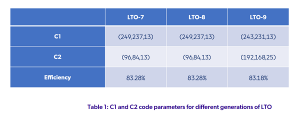
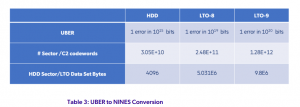
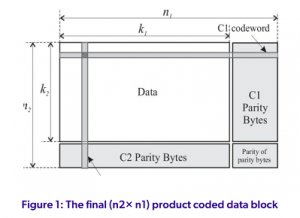 فرمتLTO ، دورهای متعددی از در هم آمیختن و پخش بایت هایی را که به همان کلمه رمز C1/C2 تعلق دارند، بر روی مکان های مختلف جدا شده فیزیکی روی سطح Tape دیکته می کند. تفکیک بین بایت های یک کلمه رمز به حداکثر می رسد تا از خطاهای مرتبط مانند نقص رسانه محافظت شود. این درهم آمیختگی عمیق منجر به خطاهایی می شود که اساساً مستقل هستند که به بهبود قابلیت اطمینان کمک می کند و در تجزیه و تحلیل ریاضی نرخ خطای بیت غیرقابل اصلاح نقش مرکزی دارد. پارامترهایی که کدهای C1 و C2 پیاده سازی شده در LTO-8 و LTO-9 را توصیف می کنند در جدول 3 زیر خلاصه شده است. جدول 3 از نماد استاندارد (n, k, d) استفاده می کند، که در آن n نشان دهنده طول بلوک،k طول پیام و d فاصله است. برای کدهای Reed Solomon استفاده شده در اینجا، d=n-k+1. هر دو کد C1 و C2 از نمادهای 8 بیتی استفاده می کنند.
فرمتLTO ، دورهای متعددی از در هم آمیختن و پخش بایت هایی را که به همان کلمه رمز C1/C2 تعلق دارند، بر روی مکان های مختلف جدا شده فیزیکی روی سطح Tape دیکته می کند. تفکیک بین بایت های یک کلمه رمز به حداکثر می رسد تا از خطاهای مرتبط مانند نقص رسانه محافظت شود. این درهم آمیختگی عمیق منجر به خطاهایی می شود که اساساً مستقل هستند که به بهبود قابلیت اطمینان کمک می کند و در تجزیه و تحلیل ریاضی نرخ خطای بیت غیرقابل اصلاح نقش مرکزی دارد. پارامترهایی که کدهای C1 و C2 پیاده سازی شده در LTO-8 و LTO-9 را توصیف می کنند در جدول 3 زیر خلاصه شده است. جدول 3 از نماد استاندارد (n, k, d) استفاده می کند، که در آن n نشان دهنده طول بلوک،k طول پیام و d فاصله است. برای کدهای Reed Solomon استفاده شده در اینجا، d=n-k+1. هر دو کد C1 و C2 از نمادهای 8 بیتی استفاده می کنند.
اگرچه این فرمت به گونه ای طراحی شده است که رویدادهای خطا را به حداکثر برساند تا عملکرد رمزگشایی محصول را به حداکثر برساند، اما گاهی اوقات به دلیل انباشته شدن خطاهای مربوط به عملیات، محیط یا مکانیک های داخلی این کار را انجام نمی دهد. در این یادداشت کوتاه، ما فقط سناریوی خطای بایت کاملاً مستقل را در نظر خواهیم گرفت، یعنی یک مدل کانال بدون حافظه گسسته (DMC) که هر بایت احتمال خطای Pbyte را دارد.
در LTO-8 و LTO-9، دو رویکرد رمزگشایی مختلف را می توان در ترکیب با کدهای محصول استفاده کرد: 1) حالت تمام خطا ( All error mode) و 2) حالت پاک کردن (Erasure mode).
All error همه خطا: در این حالت، هر دو C1 و C2 از افزونگی خود برای تصحیح خطاهای بایت استفاده می کنند، بدون اینکه هیچ کانال ارتباطی بین آنها وجود داشته باشد.
Erasure(a=1): در این حالت، کد C1 در حالت «تصحیح خطا» عمل میکند و در صورت خرابی، اطلاعات خرابی را برای موتور رمزگشای C2 ارائه میکند تا بایت مربوطه را به عنوان پاککننده علامتگذاری کند. موتور رمزگشایی C2 در حالت “تصحیح پاک کردن” با 2 بایت از برابری برای گرفتن و تصحیح یک بایت خطا در حالت (unlikely) تصحیح اشتباه C1 کار می کند. خطاهای بایت به دلیل تصحیح نادرست C1 بسیار نادر است و در صورتی رخ می دهد که رمزگشای C1 کلمه رمز اشتباهی را رمزگشایی کند و هیچ پرچم خرابی را برای C2 نشان ندهد.
قابلیت اطمینان به دست آمده با استفاده از حالت پاک کردن در بخش 4 زیر برای پارامترهای کد C1 و C2 که در جدول 1 خلاصه شده است، تجزیه و تحلیل شده است.
بخش 3 – UBER چیست؟
The INSIC 2019 technology roadmap (نرخ خطای بیت غیرقابل اصلاح) را به عنوان تعداد بیت های خطا تقسیم بر تعداد کل بیت های منتقل شده، یعنی نرخ خطای بیت واقعی پس از رمزگشایی تصحیح خطا تعریف می کند. این همان تعریفی نیست که در حال حاضر توسط صنعت HDD استفاده می شود و UBER را به عنوان احتمال خطای بخش غیرقابل جبران در تعدادی از بیت های کاربر منتقل شده تعریف می کند.
تعریف و محاسبه UBER می تواند پیچیده باشد، به خصوص که به عنوان یک نرخ خطای بیتی تعریف می شود، حتی اگر نوع خطای واقعی احتمال خرابی رمزگشای ECC است که بر اساس بخش ECC برای HDD و کلمه رمز C2 ECC برای Tapeاست. با فرض اینکه خطاها، از جمله خطاهای سطح بیت، همگی تصادفی هستند، میتوانیم بر اساس اطلاعات قالب، کلمه رمز یا نرخ خطای بخش C2 را به نرخ خطای بیت کاربر تبدیل کنیم.
به عنوان مثال، بخش HDD دارای 4 کیلوبایت بایت کاربر (32768 بیت) است. یک کلمه رمز LTO-9 C2 دارای 168 بایت کاربر (1344 بیت کاربر) است. با فرض خطاهای تصادفی، میتوانیم خرابیهای رمزگشا را به بیتهای کاربر منتقل کنیم تا UBER را بهعنوان یک رویداد خطای خواندن سخت به ازای تعداد بیتهای کاربر منتقل شده نشان دهیم، به طوری که میتوانیم LTO را با HDD با استفاده از تعاریف HDD UBER مقایسه کنیم.
با افزایش تراکم های منطقه ای، احتمال خطاهای UBER نیز افزایش می یابد، مگر اینکه از دست دادن SNR که در بخش 1 توضیح داده شده است با پیشرفت در فناوری ضبط جبران شود. برای Tape به نظر می رسد پتانسیل قابل توجهی برای ادامه مقیاس بندی [24] وجود داشته باشد، در حالی که برای چالش های HDD ناشی از حد فوق پارامغناطیس منجر به کاهش چشمگیر در مقیاس بندی شده است.
UBER تابعی از فناوری ضبط مغناطیسی، استفاده/ساییدگی رسانه و هد، شرایط محیطی، قالب داده، الگوریتم ECC و ویژگیهای خطا برای یک دستگاه ذخیرهسازی داده معین است. خطاهای غیرقابل اصلاح معمولا پنهان هستند، به این معنی که تا زمانی که فرد داده ها را نخواند، شناسایی نشده باقی می مانند. به عنوان مثال، باHDD ، یک رویداد UBER ممکن است در سطح بخش رخ دهد که در آن یک خطای پنهان و غیرقابل اصلاح در یک بخش، مانند یک نقص مغناطیسی که با فرمت ECC داخلی HDD قابل اصلاح نیست، منجر به غیرقابل استفاده / غیرقابل خواندن می شود.
بخش حتی با فناوریRAID، چنین خطاهای بخش پنهان می تواند منجر به از دست دادن داده ها شود که در طی بازسازی RAID پس از خرابی دیسک با آنها مواجه می شوند [23]. با LTO tape، خطاهای پنهان ممکن است در سطح مجموعه داده رخ دهد. با این حال، به دلیل فرمت منحصر به فرد ECC LTO که مبتنی بر کدهای تصحیح خطای 32 کانالی 2 بعدی متعامد Reed-Solomon است، احتمال یک رویداد UBER مرتباً کمتر از HDD است. با ضبط مغناطیسی، یک خطای غیرقابل اصلاح باعث می شود که بخش های جداگانه در HDD یا مجموعه های داده در LTO در دسترس نباشند. حتی با وجود اینکه عیوب رسانه اولیه معمولاً ترسیم شده است، HDD ممکن است همچنان در حین نوشتن با خطاهای پنهان مواجه شود، برای مثال خطاهای نوشتن (مانند نوشتن با سرعت بالا)، یا به دلیل نقص رسانه (نقص کوتاه یا بلند)، یا smeared soft particle. مگر اینکه داده ها به طور کامل تأیید شوند، این خطاها ممکن است شناسایی نشوند [25].
LTO دارای انعطاف پذیری داخلی برای خطاهای پنهان در حالت نوشتن است به دلیل معماری خواندن در حین نوشتن که در آن چنین خطاهای مربوط به نوشتن در حین نوشتن شناسایی و بازنویسی می شوند. علاوه بر خطاهای نویسنده، انواع دیگری از خطاهای پنهان وجود دارد، به عنوان مثال: خطاهای فرآیند پس از نوشتن که در آن مغناطیسی رسانه ممکن است کاهش یابد، یا ممکن است نقص های جدیدی ایجاد شود که منجر به خطاهای غیرقابل اصلاح پنهان می شود. اینها بیشتر به مقیاس بندی ظرفیت و فرسودگی دستگاه های ذخیره مغناطیسی برای HDD و LTO tape مربوط می شوند [26]. هارد دیسکها برای مدیریت این خطاها به پاکسازی دورهای دادهها در زمان واقعی نیاز دارند، در حالی که LTO tape میتواند به محصول ECC دو بعدی متعامد C1-C2 چند کاناله خود برای ارائه سفارشها یا میزان قابلیت اطمینان بهتر UBER تکیه کند.
بخش 4 – تجزیه و تحلیل قابلیت اطمینان LTO-9 UBER
رویدادهای خطای غیرقابل اصلاح در LTO tape بسیار نادر هستند که اندازه گیری میزان خطا را به صورت تجربی بسیار چالش برانگیز می کند. برای رسیدگی به چالش کمی کردن عملکرد کدهای تصحیح خطا LTO، هم صنعت و هم دانشگاه از محاسبات مبتنی بر مدل نظری همراه با این فرض که خطاها تصادفی و نامرتبط هستند استفاده میکنند. این مدلهای نظری مبتنی بر توزیع دوجملهای خطاهای بایت خام هستند، فرضی که به طور تجربی در شرایط نرخ خطای بالای کنترلشده تأیید شده است، جایی که این فرض به لطف در همپیچیدگی عمیق قالب [1]-[2] همچنان برقرار است. مدلهای قابلیت اطمینان پیچیدهتر که مبتنی بر تئوری فرآیندهای تجدید هستند، میتوانند خطاهای همبسته و فیلدهای هدر و همگامسازی معیوب [3] و همچنین ماهیت جداشدنی LTO tape را که ترکیبهای tape – drive چندگانه را امکانپذیر میکند، توضیح دهند.
برای تجزیه و تحلیل قدرت کدهای ECC پیاده سازی شده در LTO-8 و LTO-9، با تعریف احتمال وقوع یک خطای نماد (معمولاً یک بایت) به صورت 𝑃!”#$ شروع می کنیم (و اجازه دهید 𝑃!%# مربوط به آن باشد. احتمال خطای بیت). سپس، برای یک کد تصحیح خطا (کد کلمه) که 𝑁 بایت طول دارد که می تواند خرابی های 𝑡 را تصحیح کند. احتمال خرابی رمزگشا را می توان به صورت زیر محاسبه کرد:
تعریف HDD UBER بر اساس این معادله است.

از طرف دیگر، هر خرابی رمزگشا لزوماً به این معنی نیست که همه بایت های کلمه رمز در اشتباه هستند. برای اینکه بتوانیم نرخ خطای بایت غیرقابل اصلاح را تخمین بزنیم، از:
![]()
تعریف INSIC UBER بر اساس این معادله است. همانطور که در بخش 3 تعریف شد، UBER نرخ خطای بیت غیرقابل اصلاح است، اما بر اساس تبدیل احتمال خرابی رمزگشا به بیت های کاربر با استفاده از مشخصات فرمت است. در واقع، با فرض مستقل بودن خطاهای بیت در یک خطای بایت داده شده، میتوانیم 8 × 𝑈𝐵𝐸𝑅 ≈ 𝑈𝐵𝑦𝑡𝐸𝑅𝑅 را با توجه به مشاهدات زیر فرض کنیم:

![]()
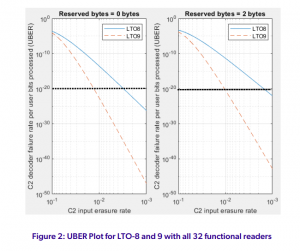
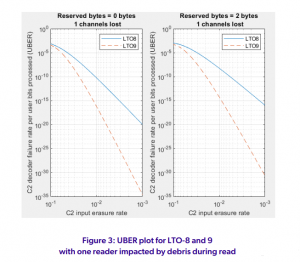
شکل 2. عملکرد کدهای LTO-8 و LTO-9 C2 را با موتور C2 ECC که در حالت پاک کردن شرح داده شده در بخش 2 کار می کند نشان می دهد. عملکرد، هر چند اشتباهاتی ممکن است رخ دهد و در این حالت شناسایی نشود، البته با احتمال بسیار کم. نمودار سمت راست حالت استفاده معمولی LTO را نشان می دهد که در آن C2 از همه برابری ها به جز دو عدد برای تصحیح خطا استفاده می کند و دو عدد باقی مانده برای شناسایی و تصحیح خطاهایی که ممکن است ناشی از تصحیحات نادرست در مرحله رمزگشایی C1 قبلی باشد، استفاده می شود. در این حالت، تمام اشتباهات برای اهداف عملی حذف می شوند. این پیکربندی منحصربهفرد دلیلی اساسی است که LTO نه تنها اعداد UBER بسیار کم را ارائه میکند، بلکه تقریباً هرگونه خطای تصحیح نادرستی را از تولید و ارسال به کاربر به عنوان داده خوب حذف میکند. شکل 3 و 4 نتایج یک تجزیه و تحلیل مشابه شکل 2 را نشان می دهد، اما یک و دو کانال از 32 کانال داده خوانده شده غیرقابل استفاده فرض می شود.
 استفاده از این نتایج برای تخمین UBER برای یک موقعیت معین میتواند کار دشواری باشد که پیچیدهتر میشود، زیرا Tape یک رسانه قابل جابجایی است و سیستم عامل Tape Drive در هنگام شناسایی خطا از تکرارهای پیچیده استفاده میکند. تلاشهای مجدد ممکن است شامل بازخوانی یک آهنگ با تنظیمات مختلف و همچنین استفاده از الگوریتمهای مختلف و تنظیمهای مختلف، از جمله بازسازی دادهها با خواندن جزئی باشد. علاوه بر این، سیستم میزبان میتواند رسانه را روی یک Tape Drive دیگر (با عملکرد بهتر) بارگذاری کند، یا هد را با کارتریج تمیزتر تمیز کند، که همه اینها میتواند به کاهش نرخ خطای ورودی کمک کند و امکان خواندن قابل اطمینان و بدون خطاهای غیرقابل اصلاح را فراهم کند.
استفاده از این نتایج برای تخمین UBER برای یک موقعیت معین میتواند کار دشواری باشد که پیچیدهتر میشود، زیرا Tape یک رسانه قابل جابجایی است و سیستم عامل Tape Drive در هنگام شناسایی خطا از تکرارهای پیچیده استفاده میکند. تلاشهای مجدد ممکن است شامل بازخوانی یک آهنگ با تنظیمات مختلف و همچنین استفاده از الگوریتمهای مختلف و تنظیمهای مختلف، از جمله بازسازی دادهها با خواندن جزئی باشد. علاوه بر این، سیستم میزبان میتواند رسانه را روی یک Tape Drive دیگر (با عملکرد بهتر) بارگذاری کند، یا هد را با کارتریج تمیزتر تمیز کند، که همه اینها میتواند به کاهش نرخ خطای ورودی کمک کند و امکان خواندن قابل اطمینان و بدون خطاهای غیرقابل اصلاح را فراهم کند.
علاوه بر کد جدید قدرتمندتر C2 که در LTO-9 پیاده سازی شده است، یکی دیگر از فناوری های جدید معرفی شده در LTO-9 برای کاهش UBER، رمزگشایی تکراری ECC است که می تواند مراحل رمزگشایی C1/C2 اضافی را برای بهبود عملکرد تصحیح خطا انجام دهد. بنابراین، اعداد واقعی UBER ممکن است بسیار کمتر از مقادیر منتشر شده در صنعت باشد، زیرا این اعداد بر اساس پاسهای رمزگشایی تکی هستند.
در شکل های 2-4، محور x نرخ های خطای ورودی (خروجی رمزگشای C1 بیان شده بر حسب پاک شدن ها) را به موتور C2 ECC نشان می دهد. میزان خطای ورودی توسط رابط Tape به سر Drive تعیین می شود که ممکن است با استفاده، الکترونیک، پردازش سیگنال کانال خواندن، فرمت و سیستم عامل کاهش یابد. این خروجی جداشده موتورهای C1 ECC تمام 32 کانال است. محور y نرخ خطای خروجی را نشان می دهد که ما آن را مقادیر UBER می نامیم. به دلیل کد قدرتمند C2 مورد استفاده در LTO-9 همراه با درهم آمیختگی متعامد دو بعدی، UBER می تواند برای خطاهای تصادفی رسانه یا حتی شرایط خارج از مسیر بسیار پایین باشد. همانطور که از شکل ها می بینیم، برای نرخ خطای ورودی 10-3، UBER نظری در خروجی رمزگشایی C2 می تواند 10-35 باشد.
با LTO-8 و نسل های قبلی، نرخ خطای ورودی EOL C2 معمولی حدود 10-3 بود، که یک هنجار برای چندین سال بود [23]. برای LTO-8 که از کد C2 (96،84،13) استفاده می کند، این منجر به UBER 10-19 شد.
LTO-9 از یک کد C2 جدید با کلمه رمز طولانی تر (192,168,25) استفاده می کند که برای خطاهای تصادفی فرض شده در اینجا قدرت تصحیح خطای قابل ملاحظه ی بهتری نسبت به کد LTO-8 قبلی دارد، همانطور که به وضوح توسط نمودارهای شکل 1 نشان داده شده است. و شکل 2.
افزایش طول کد C2 این بهبود عملکرد را با همان بازده 87.5% کد LTO-8 امکان پذیر می کند. به عنوان مثال، کدهای LTO-9 هزینه سربار یکسانی دارند، اما حفاظت از دادههای کاربر قویتر را فراهم میکنند.
شکل 1 نشان می دهد که وقتی رمزگشای C2 از 2 بایت برای محافظت در برابر اصلاحات نادرست استفاده می کند، درایو LTO-8 برای پشتیبانی از 10-19 UBER به نرخ خطای ورودی C2 کمتر از 1 e-3 نیاز دارد. با این حال، LTO-9 با فناوری جدید ECC میتواند 10-20 UBER با نرخ خطای ورودی C2 تا 9×10-3 ارائه دهد. این بدان معناست که درایو LTO-9 میتواند 10 برابر کاربر UBER بهتری را در مقایسه با LTO-8 ارائه کند، اما در محدوده وسیعتری از شرایط نرخ خطای ورودی C2، یعنی تا 9 برابر نرخ خطای ورودی C2 بالاتر.
بنابراین LTO-9 از قابلیت اطمینان داده ها در محدوده وسیع تری از شرایط عملیاتی در مقایسه با LTO-8 پشتیبانی می کند. این حاشیه گسترده تر به فعال کردن AD بالاتر LTO-9 با اطمینان از عملکرد قابل اعتماد با SNR کمتر کمک می کند. از این رو برخی از اتلاف SNR که در بخش 1 مورد بحث قرار گرفت و ناشی از 35 % TPI بالاتر و 4 % LD بالاتر است با کد بهبودیافته C2 جبران می شود، در حالی که مابقی با پیشرفت های دیگر در فناوری ضبط که در بخش 1 بحث شد جبران شده است. ویژگی کلیدی LTO-9 استحکام آن در برابر خطاهای مرتبط مانند از دست دادن موقت کانال های خواندن است. همانطور که در قسمت سمت راست شکل 3 مشاهده می شود، LTO-9 به UBER 10-20 با نرخ خطای ورودی 4 x10-3 حتی با یک آهنگ مرده/غیرقابل دسترسی دست می یابد، در حالی که حتی با نرخ خطای ورودی 4 برابر کمتر از 10- 3، LTO-8 UBER با یک مسیر مرده به 10-16 سقوط می کند. مورد دو مسیر مرده در شکل 4 تجزیه و تحلیل شده است که در آن مزایای LTO-9 حتی بارزتر است. به عنوان مثال، در پانل سمت راست شکل 4 می بینیم که با نرخ خطای ورودی 10-3، UBER LTO-8 به 10-10 می رسد در حالی که LTO-9 به UBER 10-19 می رسد. واضح است که LTO-9 در موارد خطای دنیای واقعی مانند خوانندگان مسدود شده، UBER بسیار کمتری ارائه می دهد.
بخش 5 – LTO-9 NINES of Reliability
UBER احتمال یک رخداد خطا را نشان می دهد و می توان آن را معکوس میانگین تعداد بیت های کاربر در نظر گرفت که می توان قبل از مواجه شدن با یک رویداد خطا خواند. اعداد UBER به خودی خود مربوط به آمار میانگین هستند و به طور خاص مربوط به یک دوره زمانی نیستند. به عبارت دیگر، آنها فقط نسبتی از تعداد بیت ها هستند. یک UBER خاص، زمانی که مربوط به زمان باشد، می تواند میانگین زمان بین خرابی (MTBF) برای هارد دیسک یا Tape Driveو Cartridge را به دست آورد، به عنوان مثال: با محاسبه زمان خواندن میانگین تعداد بیت های خوانده شده قبل از یک رویداد خطا با فرض حداکثر سرعت داده. جدول 2 زیر مقایسه ای بین عملکرد UBER یک هارد دیسک معمولی 18 ترابایتی با 12 ترابایت LTO-8 و 18 ترابایت LTO-9 را نشان می دهد. در این مقایسه فاکتور زمان لحاظ نشده است. درعوض، ما ترتیبات تفاوت بزرگی در UBER را بین HDD و Tape مقایسه میکنیم. در سمت راست جدول، اعداد UBER را به میانگین تعداد بایت، TB، PB و EB تبدیل کردهایم که قبل از احتمال وقوع یک رویداد خطا قابل خواندن هستند.
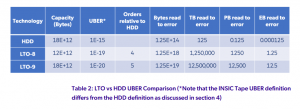 یکی از معیارهای مهم مربوط به قابلیت اطمینان، دوام است. این معیار به عنوان مدت زمانی تعریف می شود که سیستم قادر است به داده های کاربر دسترسی داشته باشد. اگر دادهها توسط یک مکانیسم افزونگی محافظت میشوند، یعنی کدگذاری تصحیح تکرار یا پاک کردن، دوام به از دست رفتن دائمی دادههای کاربر رمزگذاریشده/تکثیر شده اشاره دارد، یعنی زمانی که مقدار دادههای از دست رفته از قدرت مکانیسم افزونگی برای ترمیم فقدان بیشتر شود. واحد ماندگاری معمولاً بر حسب روز یا سال بیان می شود. با این حال، در اصطلاحات صنعت ذخیره سازی، دوام بر حسب NINES بیان می شود (9). این به احتمال عدم مشاهده خطاهای غیرقابل اصلاح در طول عملیات سیستم در یک دوره زمانی معین اشاره دارد که معمولاً یک سال در نظر گرفته می شود.
یکی از معیارهای مهم مربوط به قابلیت اطمینان، دوام است. این معیار به عنوان مدت زمانی تعریف می شود که سیستم قادر است به داده های کاربر دسترسی داشته باشد. اگر دادهها توسط یک مکانیسم افزونگی محافظت میشوند، یعنی کدگذاری تصحیح تکرار یا پاک کردن، دوام به از دست رفتن دائمی دادههای کاربر رمزگذاریشده/تکثیر شده اشاره دارد، یعنی زمانی که مقدار دادههای از دست رفته از قدرت مکانیسم افزونگی برای ترمیم فقدان بیشتر شود. واحد ماندگاری معمولاً بر حسب روز یا سال بیان می شود. با این حال، در اصطلاحات صنعت ذخیره سازی، دوام بر حسب NINES بیان می شود (9). این به احتمال عدم مشاهده خطاهای غیرقابل اصلاح در طول عملیات سیستم در یک دوره زمانی معین اشاره دارد که معمولاً یک سال در نظر گرفته می شود.
به عنوان مثال، سیستمی با 1% احتمال خرابی در یک سال، 99% احتمال عدم خرابی دارد یا قابلیت اطمینان 99% = 0.99، که قابلیت اطمینان 2 NINES است. به طور مشابه، یک احتمال شکست 0.1٪ مربوط به قابلیت اطمینان 99.9٪ یا 0.999 = 3 NINES از قابلیت اطمینان است. میزان خرابی یک هارد دیسک را می توان با معیاری به نام میانگین زمان تا خرابی (MTTF) مشخص کرد. با این حال، در یک سناریوی ذخیرهسازی معمولی، هارد دیسکها (و همچنین Tapeها) به صورت گروهی استفاده میشوند، با دادههای کاربر به علاوه مقداری افزونگی در مجموعهای از رسانههای ذخیرهسازی جدا شده فیزیکی پخش میشوند. به این ترتیب، عدم همبستگی خرابی ها/خطاها حاصل می شود. در این سناریو، یک معیار قابلیت اطمینان جدید مورد نیاز است زیرا افزونگی اضافه شده انعطاف پذیری داده های ذخیره شده را بهبود می بخشد. یک معیار شناخته شده، میانگین زمان تا داده از دست دادن (MTTDL) است. می توان MTTDL را بر حسب MTTF اجزای ذخیره سازی تشکیل دهنده سیستم با استفاده از فرآیند مارکوف برای مدل سازی ورود (وقوع) خرابی ها به سیستم محاسبه کرد.
تابع قابلیت اطمینان R(t) به طور کلی به صورت نمایی توزیع نشده است. با این حال، برای سادگی، فرض کنیم که به صورت نمایی با نرخ 1/MTTDL توزیع شده است. سپس عدد 9 به صورت زیر داده می شود:
 برای مثال، برای سیستمی با MTTDL 2500000 ساعت و زمان کارکرد 1 سال (8760 ساعت)، عدد دوام را به صورت زیر محاسبه می کنیم، R(8760) = e-8760/2500000 = 0.9965→ دو 9’s به این معنی که سیستم بدون خرابی با احتمال 0.9965 برای اولین سال استفاده در یک چرخه کاری 100% کار می کند [22].
برای مثال، برای سیستمی با MTTDL 2500000 ساعت و زمان کارکرد 1 سال (8760 ساعت)، عدد دوام را به صورت زیر محاسبه می کنیم، R(8760) = e-8760/2500000 = 0.9965→ دو 9’s به این معنی که سیستم بدون خرابی با احتمال 0.9965 برای اولین سال استفاده در یک چرخه کاری 100% کار می کند [22].
همانطور که در بالا ذکر شد، UBER عنصر زمان ندارد و از این رو تبدیل UBER به NINES قابلیت اطمینان نیاز به یک رویکرد اصلاح شده بدون عنصر زمان دارد. برای انجام این کار، یکی دیگر از معیارهای متداول قابلیت اطمینان ذخیره سازی را الهام می گیریم: کسری سالانه مورد انتظار از دست دادن داده که اندازه گیری مقدار داده از دست رفته در هنگام وقوع یک رویداد از دست دادن داده را اندازه گیری می کند و از این رو مکمل میانگین زمان از دست دادن داده است.
برای تخمین یک معیار مشابه برای HDD و Tape با استفاده ازUBER، ما در نظر می گیریم که چه مقدار داده در هنگام رخ دادن یک رویداد UBER از بین می رود. برایHDD، یک خطای بیت غیرقابل اصلاح منجر به این می شود که بخش حاوی آن بیت غیرقابل رمزگشایی شود و در نتیجه از بین برود. یک بخش HDD حاوی 4096 بایت داده کاربر است. برای یک خطای UBER 1 در 10-15 بیت خوانده شده، این مربوط به 10-15 / (4096 x 8) = 3.05E+10 سکتور خوانده شده به طور متوسط قبل از، از بین رفتن یک بخش یا 10 NINES (UBER) است. در نوار LTO، UBER بسیار کمتر از HDD است، با این حال، هنگامی که چنین رویدادی رخ می دهد مجموعه داده های حاوی آن خطا از بین می رود. در LTO-8 یک مجموعه داده حاوی حدود 5 مگابایت داده کاربر و در LTO-9 شامل حدود 9.8 مگابایت داده کاربر است. جدول 3 زیر این پارامترها و NINES(UBER) را برای HDD و LTO-8/9 خلاصه می کند.
جداول 2 و 3 نشان می دهد که احتمال مواجهه با یک خطای غیرقابل اصلاح در Tape بسیار کمتر از HDD است، با این حال، زمانی که چنین رویدادی رخ می دهد، مقدار بیشتری از داده های کاربر از بین می رود. نتیجه خالص دو مرتبه بزرگتر NINES (UBER) برای LTO-9 در مقایسه با HDD است.
همچنین یادآوری این نکته مهم است که LTO یک رسانه ذخیرهسازی بایگانی قابل جابجایی است که در آن نرمافزار میزبان میتواند مجموعهای از Tape Driveها را برای خواندن هر نواری مدیریت کند، بهویژه برای کارهای حیاتی مانند بازیابی از باجافزار که در آن خواندن بدون خطا بسیار حیاتی است. توجه داشته باشید که اعداد NINES(UBER) در جدول 3 بر اساس مقادیر EOL (پایان عمر) هستند. با این حال، با فرض اینکه میزبان قادر به مدیریت drive pool و شرایط آنها باشد، اعداد UBER ممکن است حتی بهتر از EOL UBER 10-20 فرض شده در جدول 3 باشد. برای مثال، در شکل 2 مشاهده می شود که با فرض یک عامل دو نرخ خطای ورودی بهتر برای یکdrive جدیدتر، یعنی i.e. 4.5E-3 به جای 9E-3 ، منجر به UBER LTO-9 بهتر از 10-25 می شود. این به NINES (UBER) 17 برای LTO-9 ترجمه شده است که اساساً به این معنی است که بسیار بعید است که کاربران با یک رویداد خطای خواندن سخت با LTO-9 مواجه شوند.





")
 و درایو حالت جامد (SSD)")







{kind=link}