



 چیست؟")






 در شرایط اضطراری حاکم بر کشور")









پایگاه داده اوراکل در حافظه فعال: تجزیه و تحلیل یک پایگاه داده در زمان واقعی
پایگاه داده اوراکل در حافظه (DBIM) کاملاً فشرده شده با دستورالعمل های افزایش سرعت برای نمایش داده بهینه شده است. مشتریان می توانند از Oracle DBIM برای تصمیم گیری در زمان واقعی با تجزیه و تحلیل مقدار زیادی از داده ها با سرعت فوق العاده سریع استفاده کنند. Active Data Guard (ADG) راه حل جامع Oracle برای دسترسی سریع و بازیابی اطلاعات برای پایگاه داده Oracle است.
Oracle ADG با اجازه دادن به برنامه های گزارش دهی، پرس و جوها و استخراج داده ها، با پایگاه داده همزمان و فیزیکی آماده به کار با استفاده از Oracle ADG، هزینه بالای افزونگی بیکار را از بین می برد. در اوراکل، ما مزیت DBIM را به معماری Oracle ADG گسترش دادیم. DBIM-on-ADG به طور قابل توجهی عملکرد بارهای تحلیلی، فقط خواندنی را که در پایگاه داده فیزیکی Standby در حال اجرا هستند، افزایش می دهد، در حالی که پایگاه داده اولیه به پردازش بارهای OLTP با سرعت بالا ادامه می دهد. مشتریان می توانند بر اساس الگوهای دسترسی، داده های خود را در ستون InMemory در پایگاه های اصلی و آماده به کار تقسیم کنند و از مزایای تحمل خطا بهره ببرند. در این مقاله، ما چالش های کلیدی موجود در ایجاد زیرساخت DBIM-on-ADG، از جمله تعمیر و نگهداری همزمان حافظه در پایگاه داده آماده به کار، با فعالیت OLTP با سرعت بالا را که به طور مداوم داده ها را در پایگاه داده اولیه تغییر می دهد، بررسی می کنیم.
مقدمه
Oracle Active Data Guard (ADG) همانند سازی در حالت فعال را برای پایگاه داده Oracle فراهم می کند. پایگاه داده Standby یک کپی همزمان و فیزیکی از پایگاه داده اولیه است که معمولاً در یک سایت از راه دور میزبانی می شود. Primary از طریق یک پروتکل شبکه مانند TCP / IP با پایگاه داده Standby ارتباط برقرار می کند. از آنجا که پایگاه داده Standby بخش مهمی از بازیابی فاجعه را تشکیل می دهد، به طور معمول با تأخیرهای ثانیه به ثانیه از پایگاه داده اولیه عقب می ماند، بنابراین دسترسی تقریباً بی درنگ و فقط خواندنی به پایگاه داده را فراهم می کند.
تأخیرهای زیر ثانیه برای تعدادی از برنامه های گزارش دهنده که مجموعه داده های بزرگ را پردازش می کنند، مانند تجزیه و تحلیل Big Data قابل تحمل است. بارگیری چنین بارهای کاری فقط خواندنی در پایگاه داده Standby نه تنها CPU را در پایگاه داده اولیه (تولید) برای OLTP آزاد می کند، بلکه سربارهای گزارش شده دسته ای را از پردازش آنلاین جدا می کند. شکل 1 معماری سطح بالای پایگاه داده اوراکل را که با اوراکل ADG مستقر شده است نشان می دهد.

شکل1: پایگاه داده اوراکل با Oracle ADG Standby
این مقاله نحوه عملکرد DBIM را با معماری Oracle ADG توصیف می کند تا بارهای تحلیلی در پایگاه داده Standby به طور قابل توجهی سریعتر انجام شود. معماری DBIM-on-ADG به منظور ایجاد مقیاس مستقل از پایگاه داده اولیه و همچنین آماده به کار با استفاده از Oracle Real Application Clusters (RAC) طراحی شده است، و به مشتریان مقیاس سازمانی استقلال کامل در مقیاس گذاری OLTP یا خواندن آنها را می دهد.
قابلیت گسترش ظرفیت: هنگامی که ذخیره اطلاعات در حافظه (IMCS) برای هر دو پایگاه داده Primary و Standby پیکربندی شود، داده های جمع شده در IMCS در دو پایگاه داده می توانند مجموعه ای کاملا متفاوت از اشیا باشند. این روش به طور موثر اندازه IMCS را افزایش می دهد. در یک پیکربندی معمول، مشتریان می توانند سه سرویسStandbyonly ،Primary-only و Primary-and-Standby را با استفاده از خدمات زیرساخت Oracle ایجاد کنند. همانطور که در شکل 2 نشان داده شده است، داده های جدول SALES در IMCS نمونه اولیه جمع آوری می شود، اما کل داده های SALES برای اجرای تجزیه و تحلیل در نمونه آماده به کار جمع می شوند. جداول ابعاد را می توان برای پردازش کارآمد در هر دو نمونه جمع کرد. بنابراین برای هر پارتیشن از داده های SALES، مشتری یا سرویس آماده به کار یا سرویس اصلی را تعیین می کند و برای هر جدول بعد، مشتری یک سرویس را مشخص می کند که شامل دو نمونه اولیه و پایگاه داده Standby باشد. بنابراین مشتریان می توانند با استفاده از قابلیت گسترش ظرفیت IMCS که از زیرساخت DBIM-on-ADG فراهم شده است، به انزوا در حجم کار دست یابند و از مزایای تجزیه و تحلیل سریعتر برای بارهای کاری که در هر دو نمونه اجرا می شود، بهره مند شوند.
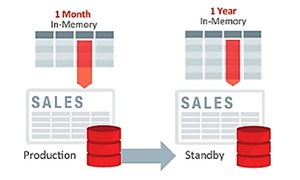
شکل 2: استقرار DBIM
تمایز از زیرساخت DBIM در پایگاه داده اولیه: معماری تکراری منحصر به فرد Oracle ADG به طراحی مجدد مولفه های اصلی زیرساخت Oracle DBIM، به ویژه مولفه هایی که داده ها را در IMCS پر می کنند و سازگاری معاملات آنها را حفظ می کند، ضروری می کند. یک چالش اساسی در هنگام طراحی معماری DBIM-on-ADG جلوگیری از به خطر انداختن مزیت اصلی ADG بود – به معنی قابل بازیابی در برابر فاجعه. قابلیت بازیابی فاجعه تابعی از سرعت همگام سازی پایگاه داده آماده به کار برای تحت فشار قرار دادن پایگاه داده اولیه است. بنابراین، زیرساخت DBIM-onADG برای افزودن لایه های فوق العاده نازک سربار بر روی معماری ADG طراحی شده است.
مروری بر معماری Oracle ADG
Oracle ADG همانند سازی فعال را برای پایگاه داده Oracle فراهم می کند.
گزارشهای مجدد ارسال شده از پایگاه داده Primary حاوی سوابق redo هستند که به طور بالقوه توسط چندین نمونه پایگاه داده Oracle (با Oracle RAC) تولید می شوند.
ورود به سیستم در پایگاه داده اولیه می تواند توسط چندین معامله همزمان ایجاد شود. استفاده از موازی سازی در پایگاه داده Standby می تواند سرعت اعمال مجدد را بسیار کاهش دهد، که به نوبه خود باعث افزایش تاخیر بین پایگاه داده های اولیه و Standby می شود. این برای هدف اصلی پایگاه داده آماده به کار و بازیابی مجدد ضرر دارد.
شکل 3 معماری سطح بالای Parallelized Redo Apply را نشان می دهد.
اگرچه موازی سازی سرعت اجرای مجدد را افزایش می دهد، اما یک مشکل ناسازگاری معاملاتی بالقوه را ایجاد می کند. به عنوان مثال در شکل 3، کاربر بازیابی 1، CV را از SCN 100 درخواست می کند، در حالی که کاربر N با سرعت بیشتری پیش می رود و CV را از SCN 110 درخواست می کند، که شامل تغییر در پایگاه داده در زمان بعدی است. در موردی که تغییرات به DBA 7 و DBA 150 بخشی از یک معامله باشد، قبل از اینکه تغییر به DBA 7 نیز قابل مشاهده باشد (به دلیل خاصیت اتمی بودن معاملات) تغییر در DBA 150 نباید نمایش داده شود.
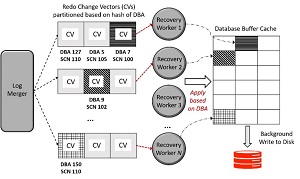
شکل 3: عملکرد موازی / بازیابی Media در Oracle ADG
یک فرایند recovery coordinator، پیشرفت کلیه فرایندهای کاربر بازیابی را ردیابی می کند. این نقطه سازگاری به عنوان “QuerySCN” در ADG نشان داده می شود. QuerySCN به عنوان سیستمی سازگار (CR) برای query های اجرا شده در برابر پایگاه داده Standby عمل می کند، تا زمانی که یک نقطه جدیدتر (یعنی QuerySCN بالاتر) توسط coordinator recovery ایجاد شود.
مولفه های خاص معماری DBIM-on-ADG برای ایجاد همان نقطه برای IMCS از نظر استراتژیک قرار گرفته اند، این امکان را فراهم می کند تا پرس و جوهایی که در QuerySCN اجرا می شوند برای استفاده از IMCS در پایگاه داده آماده به کار استفاده شوند.
مروری بر حافظه پایگاه داده اوراکل
Oracle DBIM معماری با فرمت دوتایی را ارائه داده است که دو نسخه از داده های یکسان را حفظ می کند – قالب ردیف Tradition روی دیسک و یک قالب ستونی در IMCS.
Oracle DBIM برای سرعت بخشیدن به بارهای OLTP مجهز است که پردازش تراکنش و همچنین پرس و جوهای تحلیلی را اجرا می کند.
پس از بارگیری، داده ها در IMCU با پردازش معاملات مداوم با استفاده از تکنیک های تخصصی هماهنگ می شوند. واحد متاداده (SMU) هر IMCU را همراهی می کند و اعتبار داده های جمع شده در IMCU مربوطه را در سطوح مختلف دانه بندی – سطح بلوک، سطح ردیف و سطح ستون ردیابی می کند. In-Memory Scan Engine داده های IMCU را با SMU پیوند می دهد تا اطمینان حاصل کند که داده های نامعتبر یا قدیمی از IMCS تحویل داده نمی شوند، بلکه از حافظه پنهان پایگاه داده تحویل داده می شوند. همچنین IMCU ها کنترل همزمان را انجام می دهند و عملیات هایی مانند جمع آوری مجدد، اسکن و افت IMCU را همزمان می کنند. شکل 4 تصویر سطح بالایی از معماری DBIM را با الگوهای دسترسی برای اجزای مختلف نشان می دهد.
معماری Oracle DBIM در پایگاه داده
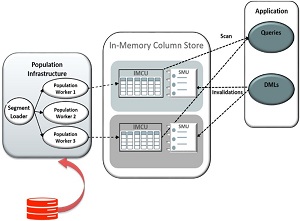
شکل 4. معماری Oracle DBIM در پایگاه داده
زیر ساخت DBIM-ON-ADG
زیرساخت DBIM-on-ADG از مولفه های ویژه ای برای جمع آوری IMCS استفاده می کند. اجزای اصلی زیرساخت DBIM-on-ADG در شکل 5 نشان داده شده است.
زیرساخت DBIM-on-ADG با پیشرفت QuerySCN در پایگاه داده آماده به کار ارتباط برقرار می کند.
سازگاری معاملاتی IMCS توسط مولفه های استراتژیک زیر حفظ می شوند:
- اجزا ining برای بازیابی و شناسایی تغییرات اشیا در IMCS.
- فراداده استخراج شده توسط مولفه استخراج در In-Memory ADG (IM-ADG) بافر شده است.
- کامپوننت Invalidation Flush این فراداده ها را در حین پیشرفت QuerySCN به SMU انتقال می دهد، بنابراین داده های اصلاح شده را در IMCU نامعتبر می کند.
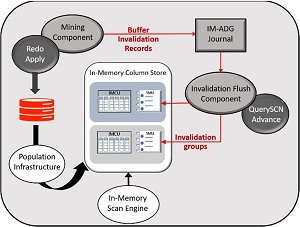
شکل5: اجزای زیرساخت DBIM-on-ADG
IM-ADG Journal
IM-ADG بافر کردن اطلاعات استخراج شده توسط مولفه استخراج DBIM-on-ADG را تسهیل می کند. IM-ADG با عملکرد های کاملاً موازی طراحی شده است، در حالی که ثابت می کند تغییرات باید در مرزهای معاملات اتمی باشند.
ساختار اصلی IM-ADG شامل یک جدول Hash Memory است که این جدول بر اساس درجه موازی سازی استفاده شده توسط معماری ADG، برای اطمینان از حداقل اختلاف بین فرایندهای بازیابی، اندازه گیری شده است.
با این وجود، با انجام تراکنش های بسیار بالا در پایگاه داده Primary، می توان از زنجیره های Hash محافظت کرد، تا بین چندین فرآیند بازیابی که در همان Hash مشابه کار می کنند همگام سازی شود.
شکل 6 طراحی سطح بالای IM-ADG را نشان می دهد.
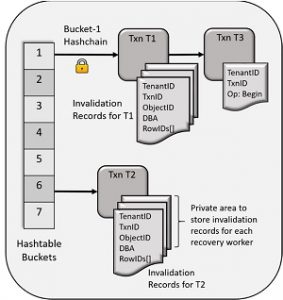
شکل 6: طراحی سطح بالای IM-ADG
همکاری مشترک:
DBIM-on-ADG Invalidation Flush Component از عملکردهای بازیابی برای کمک به این فرآیند استفاده می کند و “Cooperative Flush” را انجام می دهد.
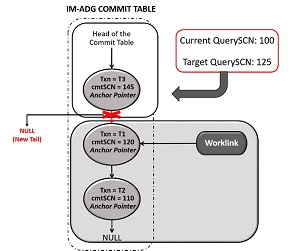
شکل7: طراحی سطح بالای جدول IM-ADG
به روزرسانی
ما زمان پاسخ سوالات Q1 ،Q2 را در پایگاه داده با و بدون DBIM-on-ADG مقایسه می کنیم. شکل 8 نشان می دهد که زمان پاسخ برای پرسش های نمونه تقریباً 100 برابر بهبود یافته است.
با اسکن سریعتر، Standby نه تنها به یک گزینه مناسب برای جداسازی حجم کار تبدیل می شود، بلکه باعث کاهش استفاده از CPU در Primary می شود. با به روزرسانی، اگر پردازش ها روی Primary اجرا شوند، از پردازنده در پایگاه داده اولیه از 11.7٪ به هنگام بارگیری اسکن ها به پایگاه داده Standby، به 4.7٪ کاهش می یابد. پردازنده Standby Database از 2٪ به 17٪ افزایش می یابد و افزایش نامتقارن به دلیل تفاوت معماری آن با پایگاه داده اولیه است.
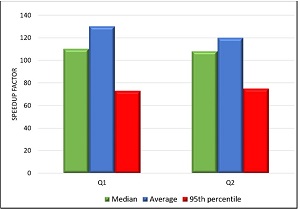
شکل 8: 95 درصد از زمان پاسخ به پرسش Q1 ،Q2 با به روزرسانی
نتیجه گیری و کار آینده
Oracle Active Data Guard دارای معماری منحصر به فردی است که امکان اجرای درخواست را در پایگاه داده Standby فراهم می کند، در حالی که به عنوان یک راه حل برای بازیابی فاجعه عمل می کند. زیرساخت DBIM-on-ADG پرس و جوهای اجرا شده در پایگاه داده را قادر می سازد تا از مزایای DBIM بهره مند شوند. DBIMon-ADG از زیرساخت موازی ADG Recovery استفاده می کند تا حافظه را در پایگاه داده Standby با فعالیت مداوم در پایگاه داده اصلی همگام سازی کند، در حالی که پایگاه داده Standby به هدف خود در زمینه بازیابی فاجعه متعهد است. با قابلیت Database In-Memory که به پایگاه داده Standby تعمیم داده می شود، مشتریان می توانند خواندن-نوشتن و فقط خواندن در پایگاه داده های اصلی، از بهترین حالت بهره مند شوند و در عین حال به تجزیه و تحلیل سریعتر بپردازند.
فعال کردن DBIM در پایگاه داده Standby این امکان را برای بسیاری از ویژگی های معرفی شده توسط DBIM فراهم کرده است و عملکرد سریع تری را برای عبارات تحلیلی پیچیده و استفاده شده در گزارش های جستجو از جمله پردازش JSON ارائه می دهد.



 ، زیرساخت امن و منعطف برای عصر دیجیتال")
 در شرایط اضطراری حاکم بر کشور")


")






{kind=link}